京东开源全球首个全栈交互AI模型 引领视频视觉语言新突破
创始人
2026-06-22 17:18:14
0次
6月22日,京东宣布开源实时视频视觉语言交互模型JoyAI-VL-Interaction,这标志着全球首个全栈开源的interaction模型和系统的诞生,同时获得vLLM-Omni的day-0原生支持。该模型突破了传统模型的局限,能够实现从“一问一答”到“边看边说”的转变,允许开发者快速构建能够持续观察、自主判断、即时响应的实景AI助手。
JoyAI-VL-Interaction在功能上实现了三重突破:首先,它能够主动判断何时发言,而不需要等待用户提问;其次,它能够实时响应视频流的变化,与传统的事后总结不同;最后,它具备后台任务委派能力,能够在处理复杂任务时,将前台模型保持在观察和交互状态。该模型支持多种视频输入,包括摄像头、直播流、监控流等,并支持语音输入输出、可视化界面、长期记忆、后台模型接口和vLLM部署方案,开发者可以根据自己的需求替换ASR、TTS、可视化界面、后台模型、外部工具和业务模块。
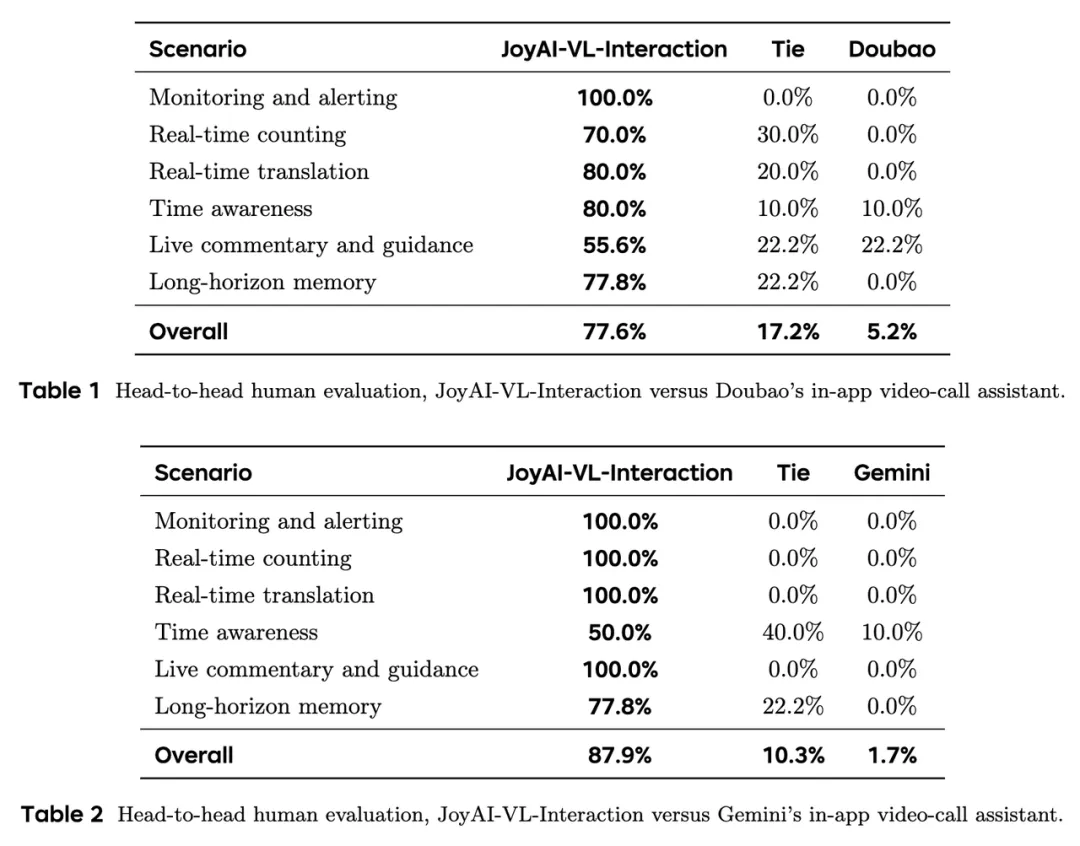
在实际应用中,JoyAI-VL-Interaction能够覆盖监控预警、实时计数、实时翻译、时间感知、直播导览解说等真实流式场景。在与视觉触发的主动响应、实时性高度相关的58个真人盲评案例中,JoyAI-VL-Interaction相较于其他视频通话助手展现出了更高的胜率,总体胜率分别为77.6%和87.9%。

相关内容
热门资讯
绍兴特斯拉Model3失控狂飙...
绍兴上虞秦先生驾驶特斯拉Model3时遭遇刹车失灵,车辆加速至110km/h后撞报废。秦先生的Mod...
百川智能发布Baichuan-...
今日,百川智能与清华大学研究团队联合发布了新一代医疗增强大模型Baichuan-M4,该模型在多个医...
保时捷成本失控,计划裁员至多4...
6月22日,保时捷首席执行官骆明楷透露,公司成本已失控,计划在7月工厂休假前与员工达成第二轮成本削减...
华为乾崑智驾ADS高阶功能包优...
今日,引望智能技术有限公司宣布了华为乾崑智驾ADS高阶功能包的最新价格调整及用户权益。自2026年7...
京东开源全球首个全栈交互AI模...
6月22日,京东宣布开源实时视频视觉语言交互模型JoyAI-VL-Interaction,这标志着全...
小米汽车纽北赛道创自动驾驶纪录...
今日,小米汽车宣布其自动驾驶汽车小米YU7GT在纽博格林北环赛道(纽北)创造了自动驾驶圈速纪录,成绩...
小米YU7GT纽北赛道创自动驾...
6月22日,小米YU7GT在纽博格林北环赛道(纽北)完成了自动驾驶测试,并以10分29秒483的成绩...
【报名】李小兵:AI来了,音乐...
主办方:羊城晚报报业集团活动时间:6月28日 14:30 至 06-28 16:30报名时间:6约2...
荔湾文化公园端午非遗体验课开讲...
为弘扬中华优秀传统文化、丰富市民假期精神文化生活,“我们的节日·端午”系列主题活动6月20日在广州荔...
中日友好人士小岛康誉:用短视频...
中新社乌鲁木齐6月21日电 题:中日友好人士小岛康誉:用短视频续写40余载新疆情缘作者 苟继鹏“在互...