全球首创!可灵AI视频O1模型:多模态交互,一键生成精准画面
创始人
2025-12-02 00:03:23
0次
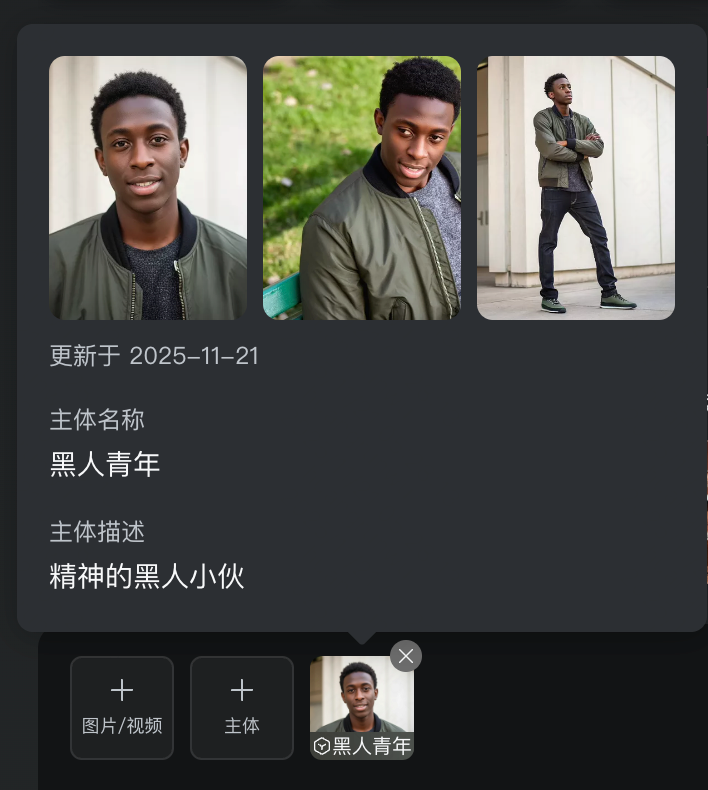
12月1日,可灵AI宣布全球首个统一多模态视频模型——可灵视频O1模型正式全量上线。这一模型通过构建全新的生成式底座,实现了功能的整合,引入了MVL(多模态视觉语言)交互架构,能够在单一输入框内无缝融合多种任务。结合Chain-of-thought技术,O1模型展现出强大的常识推理与事件推演能力,官方表示,其深层语义理解力使得每一张照片、每一个视频、每一段文字都能被视为指令。
同时,可灵AI推出了全新的创作界面,用户可以通过简单的对话轻松使用各种素材,精准生成每一处细节。O1模型支持多视角构建主体,确保无论镜头如何流转,主体特征都能稳定如一,保证画面的精准和连贯性。此外,该模型还支持自由组合多个主体,为用户提供了更多的创作自由度。


相关内容
热门资讯
极星Polestar 4 SU...
今日,极星公司宣布,其全新SUV车型Polestar 4将于9月2日正式发布。这款新车以其跨界特性,...
Momenta自动驾驶量产突破...
7月7日,中国自动驾驶公司Momenta宣布其量产业务搭载规模已突破100万台,累计交付超过100款...
奇瑞半年出口超94万辆,连续刷...
7月7日,奇瑞集团对外宣布,上半年出口量超过94万辆,连续四个月刷新中国汽车单月出口纪录。根据最新数...
广东一老人出租屋中摔伤就医,房...
近日,中山市东区朗晴假日小区发生一起房屋租赁纠纷。租客唐女士报料称,因家中老人意外摔伤、拨打120送...
岚图追光S四激光驾趣SUV 7...
7月7日,岚图汽车官方发布了追光S跃日红车色的官图,并宣布新车将在7月下旬开启预售。追光S定位为“四...
【好评中国】既要“争朝夕”,更...
“时间不等人!历史不等人!”在庆祝中国共产党成立105周年大会上,习近平总书记的话语贯穿大历史观、大...
新闻1+1丨广西防汛救援推进到...
台风“美莎克”对我国造成持续影响。6日,国家防总针对广西启动了防汛二级应急响应,广西南宁将防汛三级应...
风中雨中,有你有我
今日(7月7日),广西日报头版刊发“鼓点”评论文章《风中雨中,有你有我》。全文如下——报纸版面截图。...
视频丨战犯亲笔供词、影像留存等...
侵华战争期间,日军大肆使用各种残暴手段,对中国人民进行骇人听闻的屠杀、迫害、奴役、掠夺和摧残,造成惨...
万人说新疆 | 阿力甫:哈密木...
哈密木卡姆是流传在新疆东部哈密市的一种历史悠久、篇幅宏大、结构完整的大型维吾尔音乐套曲,共有12套。...