百度开源UnlimitedOCR:30亿参数模型,长文档解析不再慢
创始人
2026-06-25 16:16:39
0次
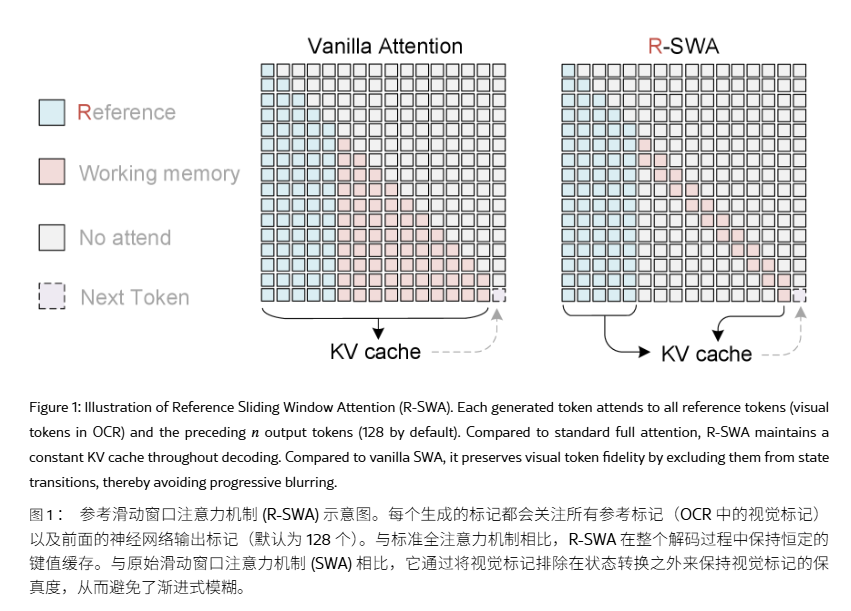
6月22日,百度开源推出了UnlimitedOCR模型,该模型拥有30亿的总参数量,但在推理时仅激活5亿参数,旨在解决端到端OCR模型在解析长文档时速度逐渐下降的问题。端到端OCR模型通过统一神经网络架构,直接从图像映射到文本序列输出,减少信息丢失和计算冗余。然而,主流模型在生成每个token时会扩大KVcache,导致显存占用和延迟上升,影响多页文档的解析效率。
UnlimitedOCR模型继承了DeepSeekOCR架构,保留了DeepEncoder与Mixture-of-Experts(MoE)解码器。在编码端,该模型采用两级视觉编码,并在连接阶段执行16倍token压缩,将1024×1024的PDF图像压缩为256个视觉token,有效减轻预填充负担。训练方面,UnlimitedOCR基于DeepSeekOCR检查点继续训练4000步,冻结DeepEncoder,仅训练解码器,使用了约200万份文档样本,运行在8×16A800GPU上。数据配比为单页与多页约9:1,多页样本通过拼接构造。
基准测试显示,UnlimitedOCR在OmniDocBenchv1.5上的整体得分为93.23,高于DeepSeekOCR的87.01和DeepSeekOCR2的89.17。其文本编辑距离为0.038,公式CDM为92.61,表格TEDS为90.93,读序编辑距离为0.045。在OmniDocBenchv1.6上,模型整体得分进一步提升至93.92。


相关内容
热门资讯
富士通PHOTON架构性能超T...
6月25日,富士通在日本宣布了其最新开发的PHOTON架构,该架构在多查询场景下的性能可达到主流Tr...
复旦大学教授张志安羊晚开讲:让...
6月24日下午,复旦大学新闻学院教授、传播与国家治理研究中心主任张志安应邀来到羊城晚报,以《城市文明...
广州荔湾桥中街道开设非遗螺钿手...
近日,广州市荔湾区桥中街道就业驿站携手广州传宇信息科技有限公司,成功举办“非遗螺钿首饰制作”就业创业...
好评中国|“青年驿站”用城市之...
当前正值高校大学生毕业季,也是找工作的冲刺期、关键期。在跨地区求职中,高昂的住宿成本、陌生的城市环境...
塔里木油田光伏阵列“染绿”近8...
天山网-新疆日报记者 于江艳 通讯员 王成凯6月24日,塔克拉玛干沙漠风光正好,大漠荒滩上,塔里木油...
活力中国调研行丨园区搭桥 助力...
科技成果转化是发展新质生产力的关键一步,也是众多高校科创团队绕不开的痛点。不少团队手握深耕多年核心技...
【牢记初心使命 奋进复兴征程】...
央视网消息:吉林磐石是中国共产党领导的东北第一支抗日武装的诞生地,是东北抗联精神的重要发源地。位于磐...
龙舟破浪 | 大美岭南·广东龙...
锣鼓震碎水乡碧波,广州番禺十乡群龙聚首。十里河道人声鼎沸,两岸街坊呐喊助威。龙舟破浪,前程万里。地点...
2030年车网互动规模达500...
6月25日,国家发展改革委与国家能源局联合发布《新型能源体系建设“十五五”规划》。规划中强调构建灵活...
新能源汽车下乡活动启动,乡村消...
今日,工业和信息化部、商务部联合国家发展改革委、农业农村部、国家能源局在新疆塔城、海南澄迈两地同步启...