阿里联手人大发布LOGOS:1B参数超越微软NatureLM,多领域科学模型开源
创始人
2026-06-18 12:53:09
0次
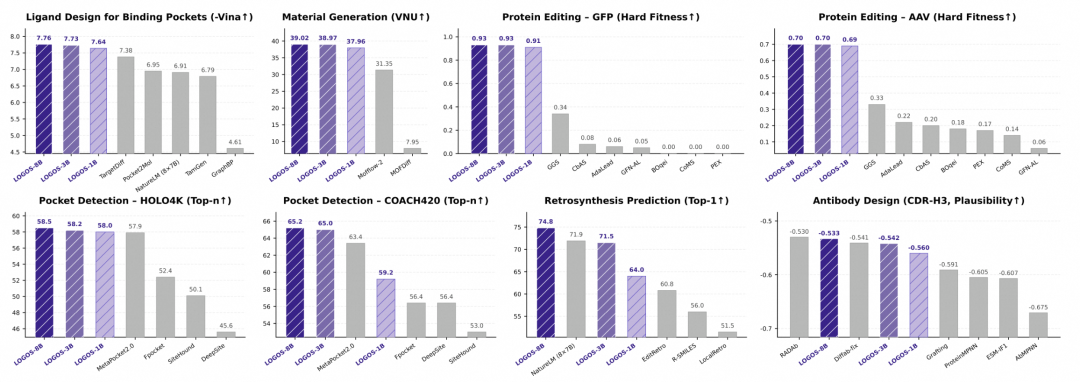
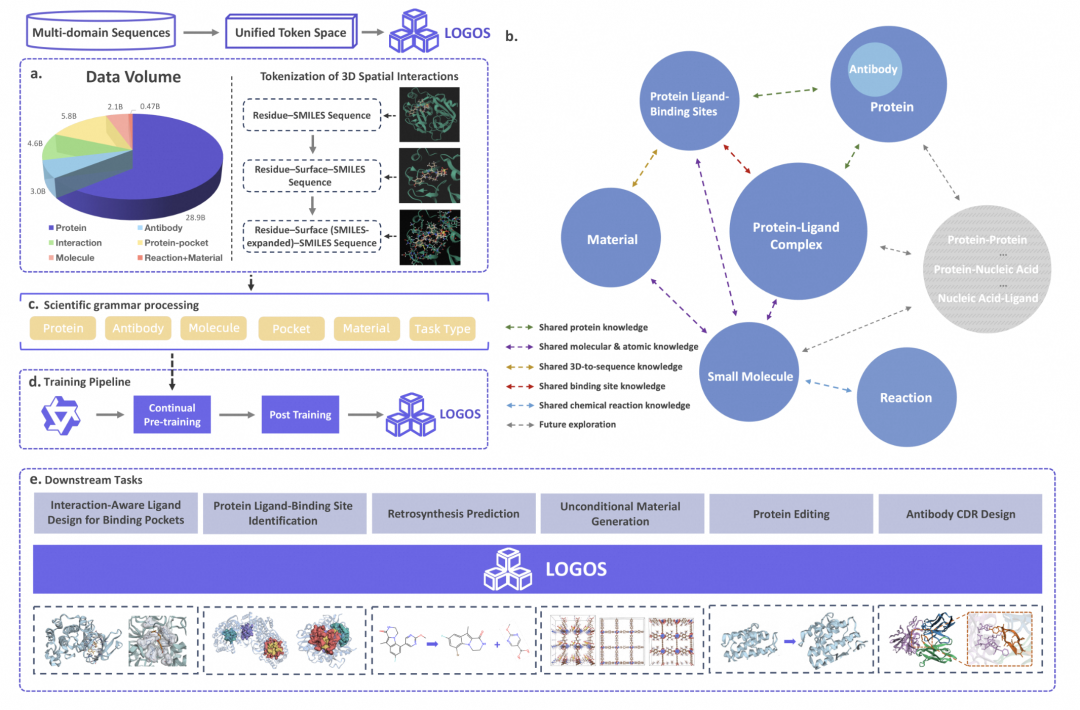
今日,阿里ATH-TokenFoundry与中国人民大学高瓴人工智能学院联合宣布,开源了首个基于统一“科学语法”的多领域科学生成基础模型LOGOS。该模型在六大科学任务上展现了卓越的性能,特别是在参数效率方面,LOGOS-1B仅用1/56的参数量就超越了微软NatureLM。LOGOS构建了一个包含7类模态、总计44.87B tokens的庞大预训练语料库,覆盖生物大分子、化学实体、材料等多个领域。
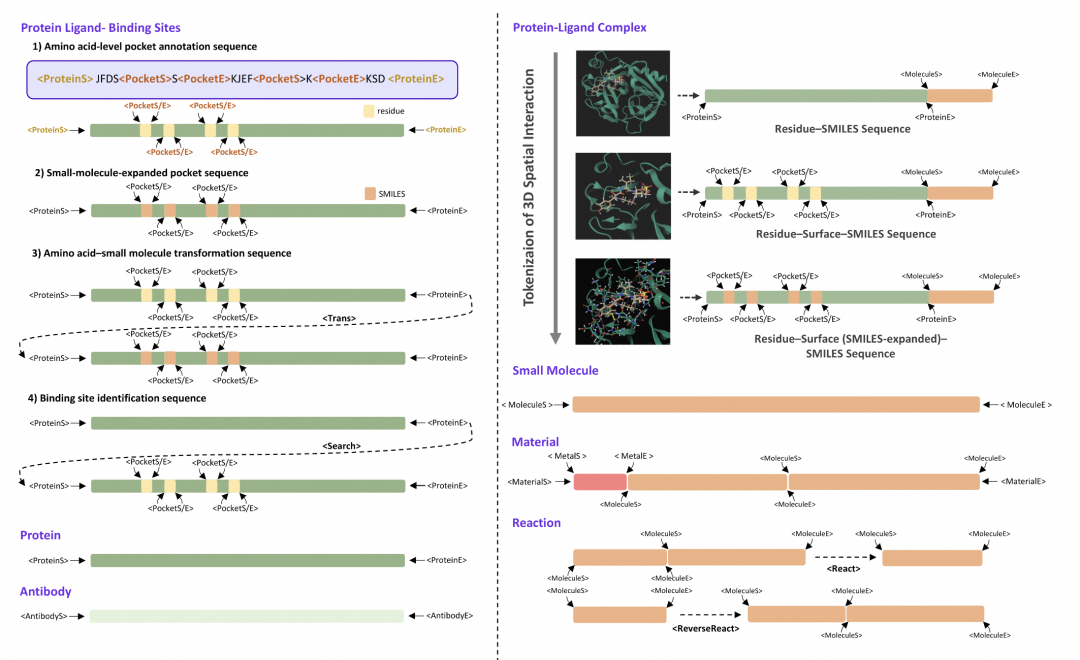
LOGOS通过设计一套共享词表,将蛋白质、小分子、材料等异构对象编码成统一的离散Token序列,实现了在同一个生成空间中的理解和生成。此外,LOGOS创新性地采用了“文字描述法”,将3D空间接触模式语法化为离散Token,无需3D坐标即可构建出复杂的3D空间互作规律。这种科学语法设计有效消除了预训练与下游应用之间的gap,无需复杂的适配层或大量微调即可激活生成能力。
LOGOS已完整开源了模型权重、推理代码与技术报告,可通过HuggingFace和GitHub访问。这一开源行动将促进科学研究的进一步发展,为多领域科学任务提供强有力的支持。
相关内容
热门资讯
26岁女子严重痛经,为不耽误工...
26岁的吴女士(化姓)是一名公司白领,平时工作节奏快,压力大。由于每次生理期都会伴有严重痛经和身体不...
6月18日起,广州中大商圈各市...
根据广州市海珠区凤阳街道有关职能部门的通告,自6月18日起,街道辖区中大商圈各市场,将全面禁入电动自...
首届超级智能体大赛启幕,广州向...
方寸之间,定格智能时代;赛场之上,激荡湾区创新。6月18日上午,首届超级智能体大赛启动暨《人工智能》...
锁住黄沙,让世界绿意盎然
新华社北京6月17日电(记者许苏培)6月17日是世界防治荒漠化与干旱日。荒漠化、土地退化和干旱是当今...
端午假期来广东,看龙舟竞渡品龙...
端午时节的广东,不少村社提供“龙船饼”这款小吃。它的最初用途,乃供俗称“扒仔”的龙舟健儿及时充饥,补...
梅州女孩被洪水卷走 三市民跳河...
众人齐心协力将落水女孩安全转移至岸边蔡潮湘回到现场,伸手指向事发河面。近日,广东梅州丰顺县汤坑镇受暴...
伟大征程 | 长江拐弯处,内陆...
长江出三峡,越江汉平原,在武汉地界猛向东折,留下一个阔大的回水湾。江水在此放缓,泥沙不再淤积,天生一...
广汽丰田铂智3X骑士版黑化上市...
6月18日,广汽丰田宣布铂智3X骑士版车型正式上市。该车型以黑化设计为特色,限量发售2000辆,建议...
阿里联手人大发布LOGOS:1...
今日,阿里ATH-TokenFoundry与中国人民大学高瓴人工智能学院联合宣布,开源了首个基于统一...
新款尚界H5上市:增程纯电双动...
6月18日,新款尚界H5正式上市,推出增程与纯电两种动力共计6款车型,售价区间为15.98-19.9...