阿里通义实验室发布语音生成新模型,自然语言指令生成语音成现实
创始人
2026-03-02 11:31:44
0次
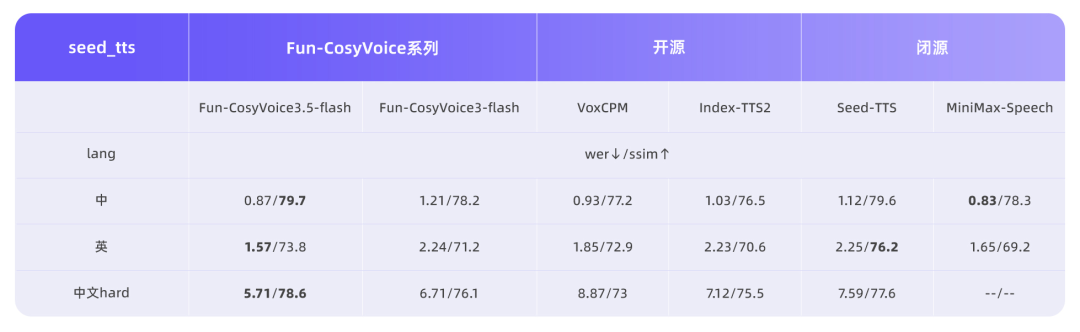
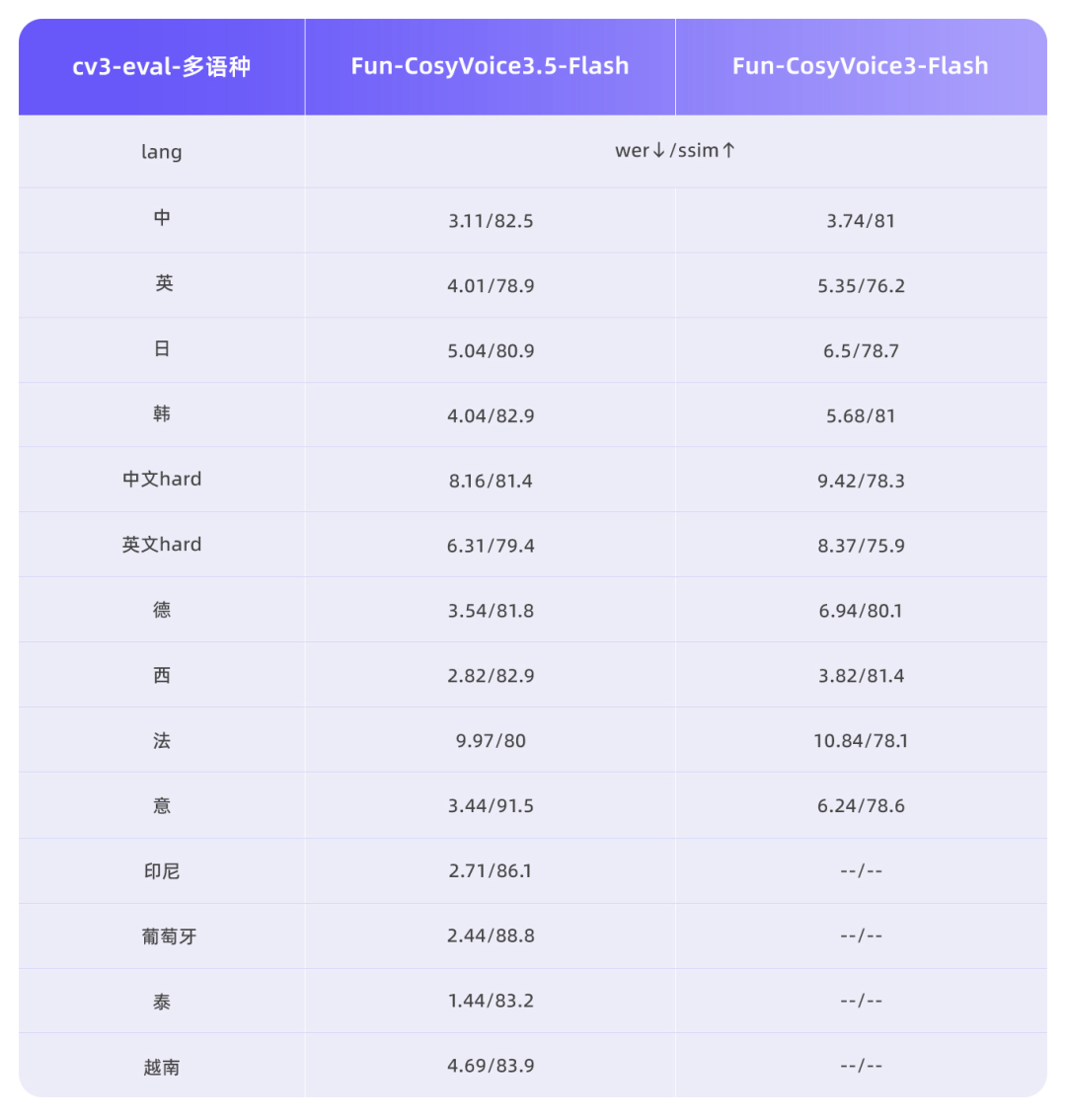
3月2日,阿里通义实验室语音团队发布了两款新型语音生成模型Fun-CosyVoice3.5与Fun-AudioGen-VD,这两款模型均支持通过自然语言指令控制语音生成,但各自应用方向不同。Fun-CosyVoice3.5模型在Instruct-TTS方向实现能力升级,支持FreeStyle指令控制生成效果,用户可以用自然语言描述表达方式,模型即可理解并生成相应表达。该模型新增支持泰语、印尼语、葡萄牙语、越南语,并在13种语言的WER和SpkSim客观指标上保持业内领先。针对生僻字、复杂语句等容易读错的场景专项优化,生僻字读错率显著降低。性能方面,Tokenizer帧率减半,首包延迟降低35%,提升了实时交互场景下的响应速度和流畅度。
Fun-AudioGen-VD模型则支持根据自然语言描述生成目标音色、情绪表达和完整听觉场景,实现“人物+场景”的一体化声音生成。该模型能够根据基础属性、音质特征、情绪表达和角色模拟等生成声音,并能叠加背景环境音、模拟空间混响效果、还原设备听感滤镜以及支持动态环境互动,打造沉浸式听觉场景。

相关内容
热门资讯
已致6死 德国北部枪击事件可能...
德国警方29日说,德国北部施塔德当天发生的枪击事件已造成6人死亡。据称,该事件可能与家庭矛盾有关。警...
强对流天气蓝色预警:陕西山西等...
央视网消息:中央气象台6月30日06时继续发布强对流天气蓝色预警,预计6月30日08时至7月1日08...
防癌医疗险能“补缺” 保障责任...
在人口老龄化加速、癌症发病率攀升的背景下,防癌医疗险备受关注。近年来,广州推出的商业健康保险产品持续...
广州对“偷面积”开出首张公开罚...
文、图、视频/羊城晚报全媒体记者 江皓轩广州市荔湾区城管执法局近日对力诚榕诚湾项目开出首张“偷面积”...
新华社访谈|在新疆,播种“梦的...
新疆巴音郭楞蒙古自治州,3000亩棉田边,艾海鹏和凌磊用手机屏幕操控着远处的无人机。飞机从棉田上方掠...
上海一高校老师发表为什么导师喜...
连日来,一篇名为《为什么导师喜欢娶自己的博士》的论文截图在网上流传开来,引发热议,第一作者署名为单福...
习近平会见白俄罗斯总统卢卡申科
6月29日上午,国家主席习近平在北京钓鱼台国宾馆会见白俄罗斯总统卢卡申科。新华社记者 申宏 摄新华社...
扛着冰箱陪“公主”参赛,省运会...
第十七届广东省运会群众赛事活动桨板比赛,这个周末在清远阳山连江河段开桨。江面百板竞发,两岸人声鼎沸。...
“AI+机器人”把关高危工作,...
文/羊城晚报全媒体记者 梁怿韬 通讯员 成广聚 陈梓佳图/通讯员提供市民丢弃的生活垃圾,最终将运至终...
师生专享多重优惠!广州从化集结...
考完试,赴一场夏日清凉之旅!为回馈2026届全国中高考毕业生、在从高校学子以及全体人民教师,广州从化...